Linux Performance Analysis & Tuning
Comprehensive guide for Linux system troubleshooting and performance optimization using modern methodologies.
Linux 性能分析与调优指南
Brendan D. Gregg
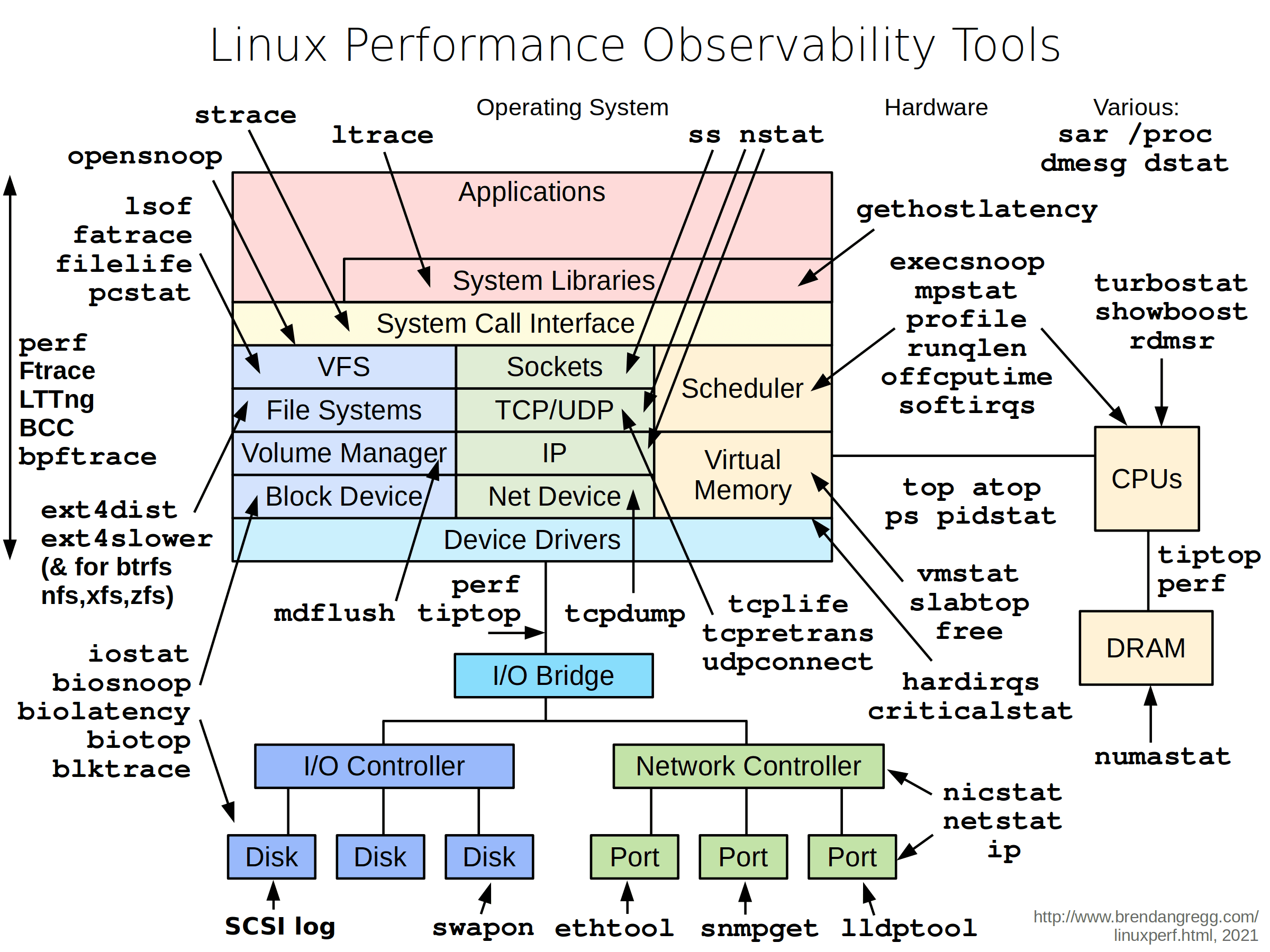
核心方法论: USE Method
在排查性能瓶颈时, 推荐遵循 Brendan Gregg 提出的 USE 方法, 针对系统中的每个资源 (CPU, 内存, 磁盘, 网络, 总线等) 进行检查:
- Utilization (使用率): 资源在特定时间内的忙碌程度 (例如: 磁盘 90% 的时间在处理请求).
- Saturation (饱和度): 资源排队等待的工作负载 (例如: CPU 运行队列长度).
- Errors (错误): 资源发生的错误事件 (例如: 网卡丢包, 磁盘超时).
黄金 60 秒: 快速排障 Checklist
当你登录一台性能异常的服务器时, 请在 60 秒内运行以下命令获取系统全貌:
1. 基础负载观察
uptime # 查看 Load Average (1, 5, 15 min)
dmesg -T | tail -n 50 # 检查内核错误、OOM、硬件告警2. 资源分布快照
vmstat 1 # 综合观察 CPU 状态(r, b), 内存(swpd, free), IO(bi, bo)
mpstat -P ALL 1 # 检查是否存在单核 CPU 性能瓶颈 (软中断、热点核心)
pidstat 1 # 找出消耗 CPU 的具体进程及上下文切换情况3. I/O 与存储
iostat -xz 1 # 观察磁盘利用率 (%util) 和延迟 (await)
free -h # 内存剩余及 Cache/Buffer 情况4. 网络健康度
sar -n DEV 1 # 检查网卡吞吐 (rx/tx) 是否达到物理上限
sar -n TCP,ETCP 1 # 检查 TCP 连接速率及重传数 (retrans/s)深度调优: 资源专项深入
1. CPU 优化
- 现象:
top中User%过高通常是代码逻辑问题;Sys%过高则说明系统调用频繁或内核锁竞争严重. - 工具:
perf top: 实时查看消耗 CPU 最多的内核函数或用户态符号.perf record -g -p <pid>: 导出采样数据, 生成火焰图 (Flame Graphs) 进行可视化分析.
- 调优策略:
- 绑核 (CPU Affinity): 减少 CPU 缓存失效.
- 调度优化: 调整
nice值或实时优先级 (chrt).
2. 内存优化
- 现象:
free接近 0 并不代表内存不足 (关注available), 但Swap增大通常预示着性能急剧下降. - 工具:
slabtop: 观察内核内存分配情况 (常用于排查内核内存泄漏).cat /proc/meminfo: 获取极致详细的内存统计.
- 调优策略:
- HugePages: 对于大型数据库或 JVM, 启用大页内存可显著减少 TLB 缺失.
- Dirty Ratio: 调整内核刷盘频率以平滑 IO 抖动.
3. I/O 优化
- 现象:
iostat中await远大于svctm, 说明 IO 队列严重饱和. - 工具:
iotop: 查看谁在疯狂读写硬盘.blktrace: 对块设备请求进行极致细粒度的追踪.
- 调优策略:
- IO 调度算法: 对于 SSD, 推荐使用
none或mq-deadline. - 预读 (Read-ahead): 针对大序列读取场景调优
blockdev --setra.
- IO 调度算法: 对于 SSD, 推荐使用
4. 网络优化
- 现象:
retrans/s非零通常意味着网络丢包或拥塞. - 工具:
ss -ntip: 查看 Socket 详细状态及内部参数 (如 RTT、拥塞窗口).tcpdump: 抓包分析协议栈异常.
- 调优策略:
- 内核协议栈: 调整
tcp_rmem/tcp_wmem提高吞吐. - 零拷贝: 优化应用逻辑减少数据拷贝次数.
- 内核协议栈: 调整
专家武器库: eBPF 与高级追踪
在现代 Linux 运维中, eBPF 已经成为了标准配置:
- bpftrace: 快速编写临时脚本执行深度探测.
# 查看哪些进程正在调用哪个文件 bpftrace -e 'tracepoint:syscalls:sys_enter_openat { printf("%s %s\n", comm, str(args->filename)); }' - bcc-tools:
opensnoop: 追踪所有文件打开操作.biolatency: 以直方图形式展示 IO 延迟 distribution.tcptracer: 追踪 TCP 连接全生命周期.
性能调优 Checklist (内核侧)
在 /etc/sysctl.conf 中, 一些常见的专家级参数参考:
# 提高文件描述符限制
fs.file-max = 2097152
# 加速 TCP 连接回收, 应对高并发
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_fin_timeout = 30
# 增加 TCP 监听队列上限
net.core.somaxconn = 65535
# 优化内存分配时的内核保留空间
vm.min_free_kbytes = 1048576
# 控制换出倾向, 物理内存足够时设低
vm.swappiness = 1专项进阶: 突发重启排查 (Post-Mortem Analysis)
1. 区分重启性质 (软重启 vs. 硬重启)
运行 last reboot 和 who -b 仅能确认重启时间, 关键在于区分:
- 软重启: 内核主动发起的重启 (如 OOM, Kernel Panic). 通常能在日志中捕捉到 "最后一言".
- 硬重启: 硬件层面掉电或 Reset (如电源故障, CPU 过热, 主板故障). OS 往往来不及写日志, 表现为日志文件中的 "空洞" (Time Gap).
2. 日志追溯 (The Last Words)
检查重启前几秒的系统日志:
# 查看上一次开机周期的最后日志
journalctl -b -1 -n 1000
# 搜索关键关键字: Panic, Oops, OOM, thermal, MCE
grep -Ei "panic|oops|out of memory|mce" /var/log/messages3. 配置 Kdump (捕获内核崩溃)
对于 Kernel Panic 引起的重启, 必须配置 Kdump. 当内核崩溃时, 它会启动一个临时的 "捕获内核" 将当前内存镜像 (vmcore) 保存到磁盘.
- 安装:
yum install kdump-utils或apt install kdump-tools. - 配置: 需在 grub 中保留内存 (如
crashkernel=256M). - 分析: 使用
crash工具分析生成的/var/crash/下的数据.
4. 硬件带外管理 (IPMI / SEL)
如果是硬件导致的硬重启, OS 日志是看不到任何东西的. 这时必须查看服务器的 SEL (System Event Log):
# 使用 ipmitool 查看硬件事件
ipmitool sel list
ipmitool sel elist重点搜索: Power Unit (电源故障), Temperature (过热), CATERR (CPU 内部错误).
5. Pstore (持久化存储)
在一些现代系统上, 内核支持将崩溃日志保存在 RAM 的特定区域或固件 NVRAM 中, 即使重启也不会消失.
- 检查
/sys/fs/pstore/目录下是否有文件.
6. 配置串口控制台 (Serial Console)
对于极致的排障, 建议将系统日志同步输出到串口. 即使文件系统因为 Panic 挂载为只读, 串口依然能实时打印出完整的 Panic 调用栈 (Call Stack).
Checklist
- 检查
journalctl -b -1是否有 OOM 或 Panic 信息. - 检查
ipmitool sel是否有硬件告警. - 确认
kdump服务是否处于 active 状态. - 检查
/var/log/mcelog(针对硬件错误校验).
7. 实战: 使用 crash 分析 vmcore
当你有了 /var/crash 下的文件, 真正的“破案”就开始了.
准备工作
crash工具: 专门解析内存转储的调试器.- 带调试符号的内核 (vmlinux): 必须与崩溃时的内核版本精确匹配 (通常是
linux-image-*-dbg或kernel-debuginfo).
# 启动分析 (需要管理员权限)
crash /usr/lib/debug/boot/vmlinux-$(uname -r) /var/crash/202512181200/vmcore“三板斧”定位法
sys: 查看 PANIC 字符串, 锁定初步死因.bt: 最核心命令. 查看 Backtrace, 寻找带*的函数, 特别是来自第三方驱动 ([module_name]) 的函数.log: 读取内核环形缓冲区末尾的遗言.
进阶技巧
ps: 查看崩溃瞬间所有进程的状态.files <pid>: 破案核心. 能够显示特定进程在崩溃瞬间打开了哪些文件 (路径, INODE, 类型). 如果进程卡死在 I/O 读写上, 这是定位目标文件最快的办法.vm <pid>: 内存布局分析. 展示进程的虚拟内存映射 (类似 maps), 用于排查内存损坏、非法地址访问或共享库加载问题.dis <address>: 反汇编异常指令, 查出是哪行代码在访问非法地址.
其他高频运维命令
kmem -i / -s: 检查系统物理内存和 Slab 缓存是否存在泄漏或耗尽.mount: 查看崩溃时的文件系统挂载状态.dev: 列出系统中所有的设备驱动状态.net: 查看网络 Socket 连接和网卡统计.
专家级调优: 硬件亲和性与系统损耗
在多路服务器或高并发场景下, 默认配置往往无法发挥硬件的极致性能.
1. NUMA 架构调优
现代多路服务器采用 NUMA (Non-Uniform Memory Access) 架构. 访问远程 CPU 插槽连接的内存会有更高的延迟.
- 现象: CPU 利用率不高但响应慢,
vmstat显示大量的cs(上下文切换) 或sy(系统时间). - 工具:
numactl -H: 查看节点的内存分布.numastat: 观察内存分配是否平衡, 统计numa_hit和numa_miss.
- 策略:
- 绑核策略: 使用
numactl --cpunodebind=0 --membind=0 ./prog确保进程在同一个 NUMA 节点内运行. - 内存平衡: 调整
vm.numa_balancing=1让内核自动迁移页面, 或根据场景关闭它以减少 CPU 开销.
- 绑核策略: 使用
2. 中断均衡 (IRQ Affinity)
高并发网络或磁盘 I/O 下, 默认的 irqbalance 可能将中断分配不均, 导致个别核心被打爆 (软中断 %soft 过高).
- 现象:
mpstat显示某个核心的%soft显著高于其他核心. - 调优:
- 手动绑定网卡中断到特定核心:
echo <mask/cpu_list> > /proc/irq/<irq_num>/smp_affinity_list. - 对于万兆及以上网卡, 开启 RSS (Receive Side Scaling) 并合理配置核心分布.
- 手动绑定网卡中断到特定核心:
3. 系统抖动优化 (System Jitter)
在 HPC 或实时任务中, 需要减少内核背景任务对计算任务的干扰.
- 隔离核心 (CPU Isolation): 在引导参数中使用
isolcpus=1-11将这些核心从内核调度器中剥离, 仅供特定任务使用. - 禁用频率自适应: 将 CPU 调频模式设为
performance, 避免电压/频率切换带来的微量延迟.cpupower frequency-set -g performance
4. Systemd 资源控制
在 DevOps 流程中, 应该利用现代 Cgroups 机制在服务层面做限制, 而不是依赖应用自身配置.
- 在
.service文件中配置:[Service] # 限制 CPU 使用率硬上限 CPUQuota=80% # 内存限制与软限制 MemoryMax=2G MemoryHigh=1.8G # IO 限制 IOReadBandwidthMax=/dev/sda 10M
建议
- 先观测, 再猜测, 最后调整: 不要凭直觉改参数, 每一个调整都应该有数据支撑.
- 一次只改一个变量: 修改后观察 24 小时的稳定性, 确认不再有重启或性能抖动.
- 建立性能基准线 (Baseline): 没有平时的正常数据作为对比, 你无法识别什么叫 "异常".